
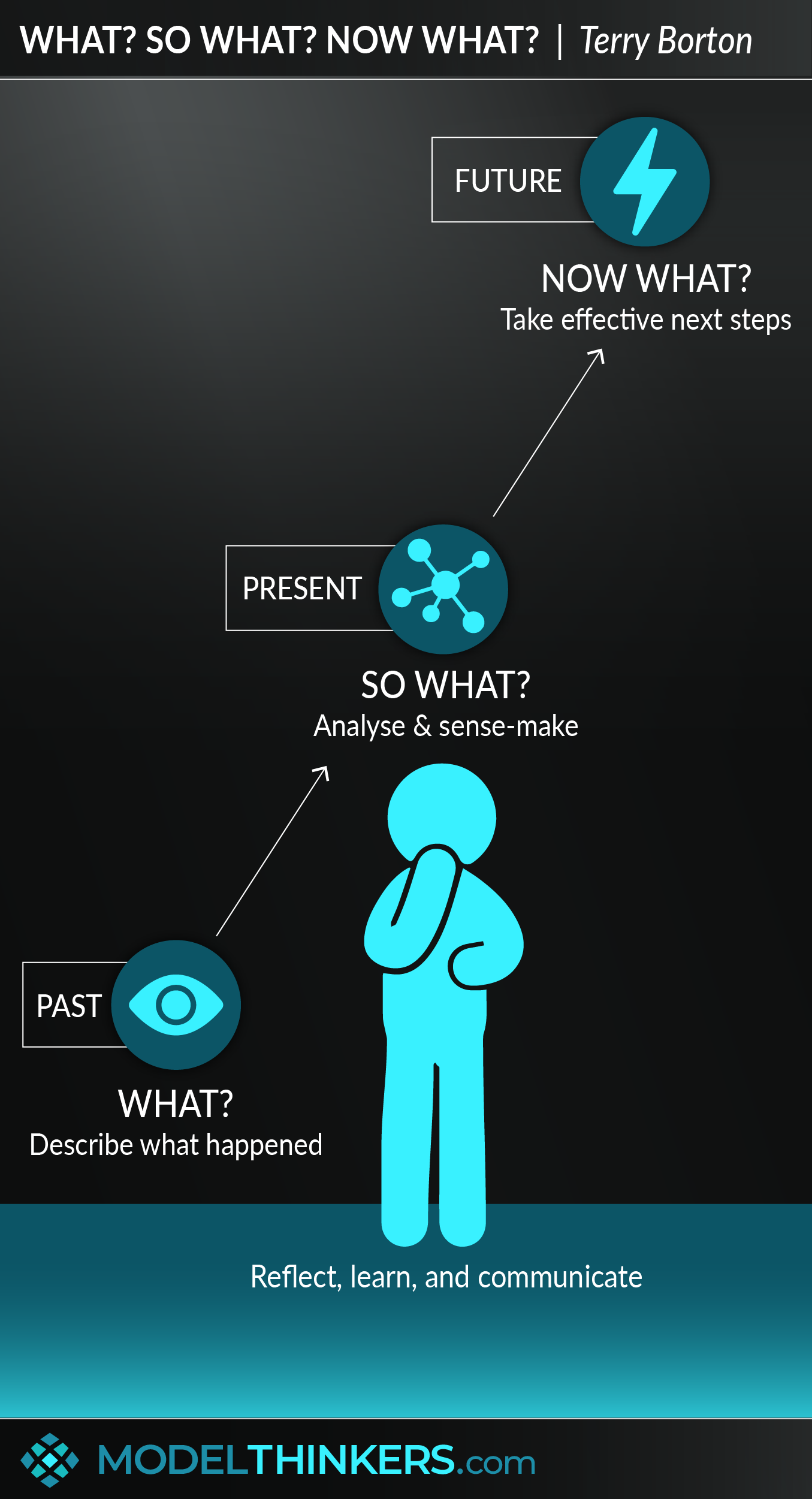
Alright, let’s dive into this “model wek” thing. It was a bit of a rollercoaster, not gonna lie, but hey, that’s how we learn, right?
The Initial Idea: So, I had this grand vision of streamlining our data processing pipeline. We were drowning in spreadsheets, and the whole process was just…clunky. I figured, why not build a model that automates a chunk of it? Seemed simple enough at the start. I wanted to see if I could automate more of my workflow.
Getting My Hands Dirty: First things first, data collection. This was a mess. Different departments used different formats, some data was missing, you name it. I spent a good week just cleaning and standardizing everything. I used Python with Pandas, mostly. Learned a lot about handling missing values and inconsistent data entries. Seriously, data cleaning is like 80% of the work, I swear. I remember thinking, “Is this what data scientists actually do?”
Choosing the Model: Okay, with the data somewhat presentable, it was time to pick a model. I considered a few options – regression, maybe some classification stuff. I settled on a simple linear regression model using scikit-learn in Python. It wasn’t perfect but was the best to get me started. I knew the relationships weren’t perfectly linear, but I wanted a baseline to compare against.
Training and Testing: Next up, training the model. I split the data into training and testing sets (80/20 split). I was super excited, ran the training, and… the results were underwhelming. The R-squared value was terrible. I started questioning my life choices. I spent a lot of time scratching my head.
Tweaking and Tuning: Okay, panic mode averted (sort of). I started playing around with different features, adding some interactions, and trying different scaling techniques. I even tried a polynomial regression to capture some non-linearities. Things improved, but not by much. I felt like I was throwing darts in the dark, hoping something would stick. But then I tried another method.
Deeper Dive: Turns out, I was missing a key variable. After talking to the domain experts (which I should have done earlier, duh!), I realized that a specific external factor was heavily influencing the outcome. I incorporated this factor into the model, and BAM! The R-squared value jumped significantly. I was ecstatic! Sometimes, the solution is simpler than we think.
The Final Stretch: With the model performing decently, I focused on deployment. I containerized the model using Docker and deployed it to a cloud platform. I even created a simple API endpoint using Flask so that other teams could easily access the model’s predictions. It’s like putting the cherry on top of an ice cream sundae.
Lessons Learned: So, what did I learn from this whole “model wek” ordeal? First, data cleaning is crucial. Second, domain knowledge is invaluable. And third, don’t be afraid to ask for help. Building models is an iterative process, and it’s okay to make mistakes along the way. It’s all about learning and improving. Oh, and start with a simple model. It’ll save you from a headache.
Next Steps: I am planning to keep improving the model, exploring other algorithms and data sources. I’d also like to create a more user-friendly interface for the API. This is just the beginning!



